Combining Data Structures
Introduction
One very common feature in many programming languages is called lexical scoping. This feature restricts the use of variable names to be within the (lexical) scope they are defined in. A very common way to map variable names in a scope to values within the compiler is to use a hashmap to use a string to get the variable’s value. Implementing nesting scopes is fairly simple as the current state at any point in the program can be represented using a stack of hashmaps. Every time a scope is entered, a hashmap is pushed onto the stack, and every time a scope should exit, a hashmap is popped from the stack. Variable declarations get added in the top-most hashmap and variable lookups start at the top of the stack and work down the stack if the variable name isn’t found at the current level.
Common Implementation
Many guides about making a programming language use the strategy of making a stack of hashmaps to enforce lexical scoping. The way they implement is often similar to: (Java) Stack<HashMap<String, Value>>, or (C++) stack<unordered_map<string, value>>. While implementing this data structure from scratch, I realized something inefficient in the guide’s implementation. It’s not the use of standard library data structures (or at least that’s not what this blog discusses), the problem is treating each basic data structure completely separately. The data structure implemented is not a stack of hashmaps, but more accurately as a stack that happens to contain hashmaps as its payload. Treating it this way greatly restricts the potential to optimize for the overall data structure, which is ultimately what matters.
Combined Implementation
By recognizing the fact that only the top hashmap can be added to, we can store all of our hashmaps tightly within one contiguous memory allocation. This means that the interior hashmaps would not have room to grow if they needed to, which is acceptable since we never add to the interior hashmaps. Only the top hashmap is allowed to grow. There are many ways to ensure there is enough memory for the top hashmap to grow into. The way my implementation achieves this is by allocating the whole data structure in one very large, continuous chunk of memory. As modern operating systems only map memory you use to physical memory, if only a small amount of memory is used, only a small amount is physically allocated.
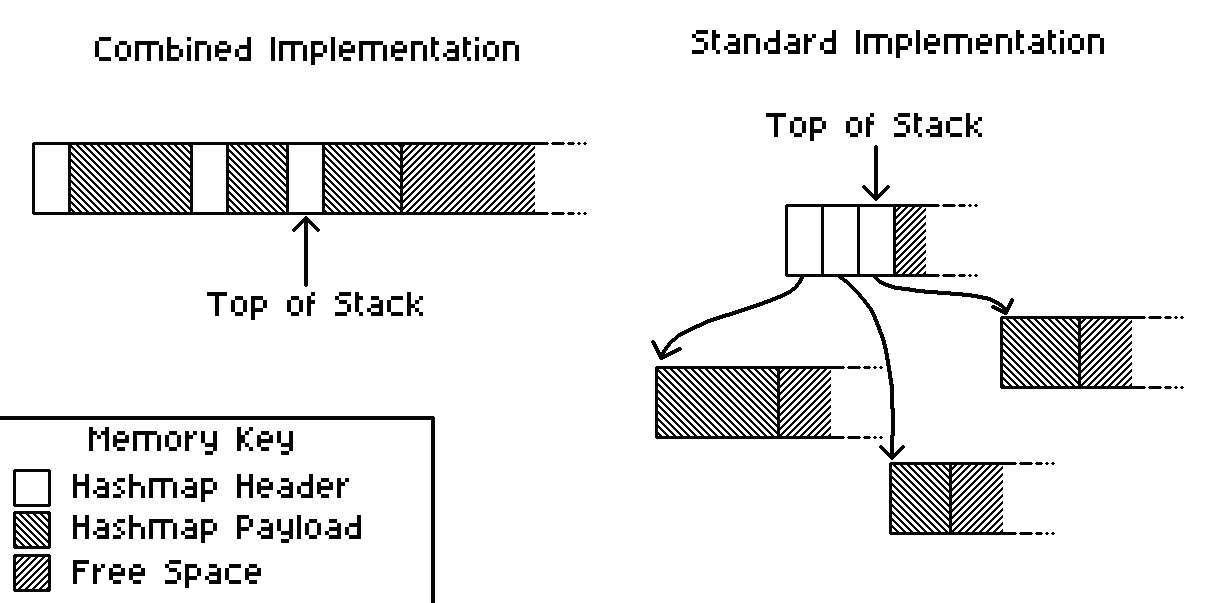
Comparison of the memory layout of the combined stack-of-hashmaps versus the separated stack of hashmaps
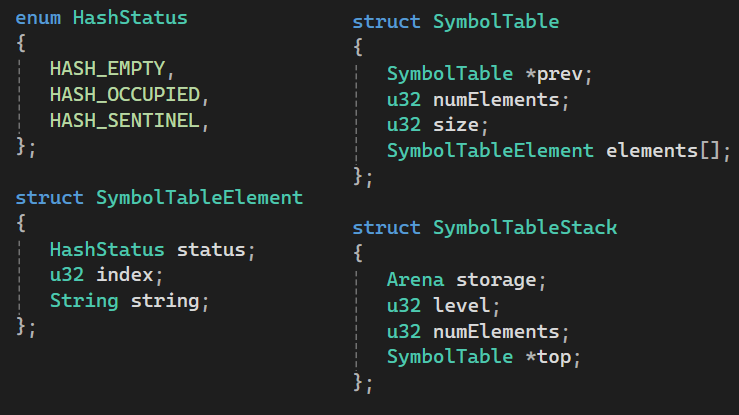
All the structs used to store the stack-of-hashmaps data structure. All of the SymbolTables and corresponding Elements are stored in the “storage” Arena
Benefits
One benefit of a unified stack-of-hashmaps data structure is less memory fragmentation. Treating the hashmaps separately would imply separate allocations for each hashmap, likely dispersing unpredictably throughout the virtual address space. Storing all of the hashmaps tightly packed makes for better cache and TLB locality, especially when searching through multiple maps. Another benefit is the convenience that everything is stored in only one contiguous allocation. This results in less round trips to a dynamic allocator and less work when deallocating the data structure for both the program and the programmer.
Tradeoffs
There are some tradeoffs when taking this approach. It is harder to reuse already existing code when building the combined data structure and we can’t easily make use of the standard library data structures for it. The flexibility of the data structure is also limited as key assumptions are exploited and if they change the data structure has to, as well. There may also be additional mental overhead when combining several complicated data structures, which could lead to buggier implementations.
Conclusion
While I imagine these optimizations are not critical or do not yield a massive performance boost, I found this exercise to be quite interesting and wanted to share it. I expect that down the line this strategy would provide more significant benefits for me, and I hope that you can find some opportunities to use this method in your project.